The Scent
Last week, our users started seeing errors that didn't make sense. Sometimes opening a project would fail. Sometimes cloning code from GitHub would time out. We were even seeing the dreaded "Connection reset by peer". There was no real obvious pattern, which is always the worst kind of pattern.
On a platform like Lovable, which currently creates more than 50 sandboxes per second during peak hours, even a small percentage of failures can be a big problem for our users. Something in our infrastructure was wobbling, and we needed to find it.
Following the Trail
Sascha, one of our infrastructure engineers, started where any good debugging session begins: the logs. But we had millions of log lines to sift through, and patterns weren't jumping out. He decided to try something new. He'd been experimenting with AI agents for debugging, and this felt like the right moment to lean on them. He set up an agent with access to our Clickhouse logs and started asking it questions. The agent surfaced a suspicious issue: the anetd pods in our Google Kubernetes Engine cluster were restarting constantly, around 120 restarts per pod over six days, which is almost one crash per hour. Surely, this couldn't be right!
For context, anetd is Google's implementation of Cilium, the networking layer inside our Kubernetes clusters. When anetd crashes, new pods can't get network interfaces. And when your entire product depends on spinning up fresh sandboxes continuously, networking instability quickly translates into user-facing failures.
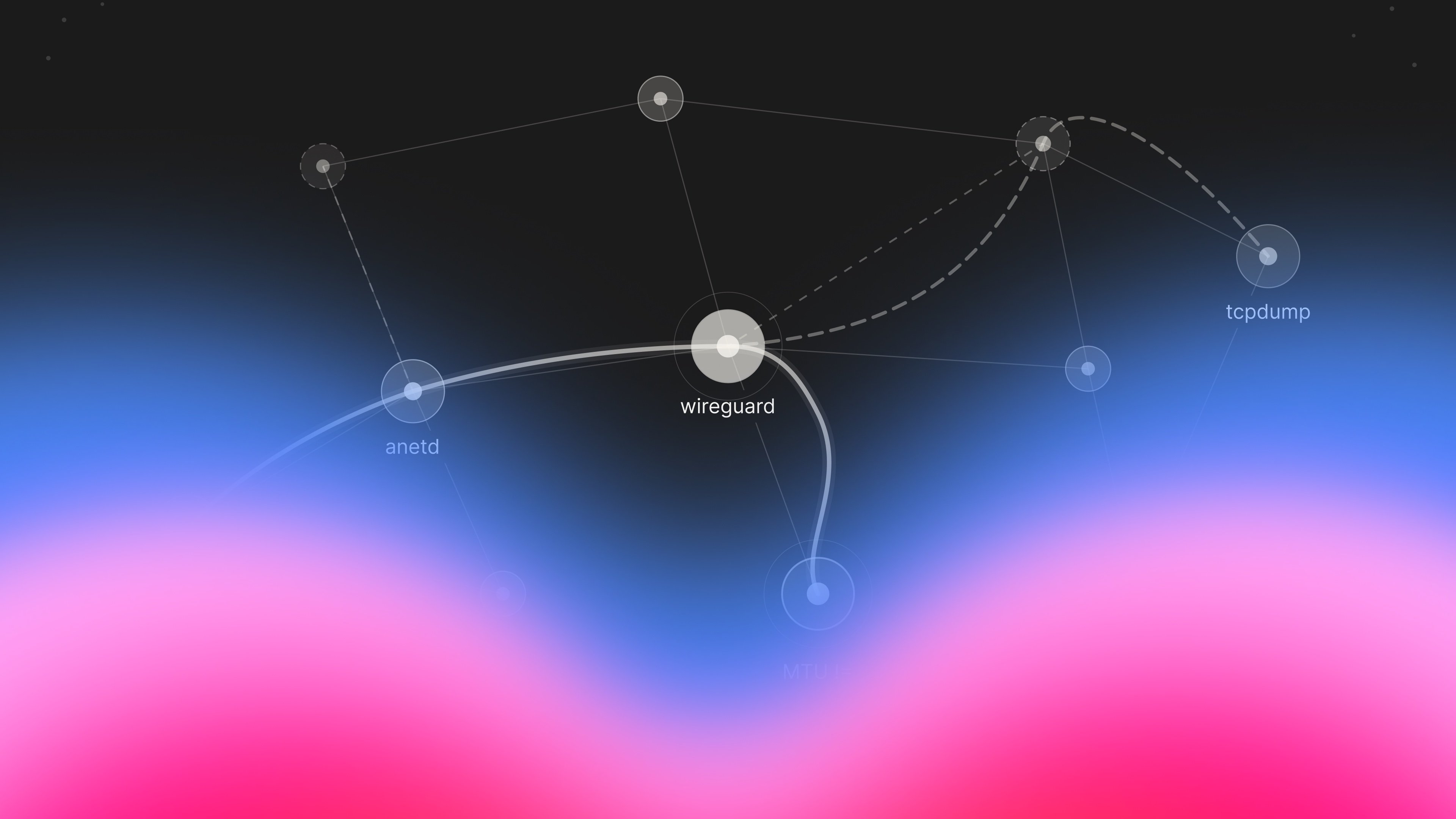
Sascha dug into the crash dumps. The stack trace pointed to a concurrent map-access panic, multiple goroutines trying to read and write to the same data structure at the same time without proper locking. But the key detail was where the panic happened: inside the Wireguard module of anetd.
WireGuard itself is an open-source encryption protocol, which Google does not own. But they do own the code that integrates it into anetd, their networking daemon for GKE. The panic was happening in Google's integration code, specifically in how they were managing concurrent access to a map data structure that tracked Wireguard connections.
This matters because it means the bug was in Google's implementation, not in WireGuard itself. Ergo, we'd need Google's help to fix it.
Pulling in Support
We got on a call with Google's account team. It was a Sunday, but this was affecting users, so the team assembled. Their representative's recommendation was straightforward: disable transparent node-to-node encryption. This would bypass whatever bug we were hitting in the WireGuard module entirely.
We talked through the tradeoffs. Disabling encryption between nodes wasn't ideal from a security perspective, but our cluster already ran on Google's private network, and stable is better than perfect when users are seeing errors. We rolled out the change, restarted all the anetd pods, and watched the dashboards. The crashes stopped. For about four hours, we thought we were done. Some of the team logged off. Then the Slack notifications started rolling in again.
A Second Trail
We were seeing random connection failures to Valkey, our in-memory data store.
At first, we suspected Valkey itself. CPU usage was climbing. We doubled the node count to make sure it wasn't saturated. Sadly, the errors kept coming.
Erik, another engineer on the call, had a hunch. We hadn't changed any application code, so the problem had to be deeper in the stack. Probably networking. He spun up tcpdump on a few nodes and started capturing packets.
The rest of the team chased other potential leads while he filtered through the traffic in Wireshark. Then he found the smoking gun:
"Destination unreachable (Fragmentation needed)."
That's when everything started to click for us.
The MTU Mismatch: "We're gonna need a bigger packet."
Here's what was happening: When WireGuard was enabled, our cluster used an MTU (maximum transmission unit) of 1420 bytes to account for WireGuard's encryption overhead. Normally, Ethernet uses a standard MTU of 1500 bytes.
When we disabled WireGuard, we expected the configuration to change to use the full 1500 bytes. However, some nodes in the cluster hadn't been restarted yet. They were still using the old 1420-byte MTU.
This particularly affected Valkey connections because they were distributed across nodes with mismatched MTU settings. So depending on which node your API pod was running on, you might connect fine... or fail mysteriously. The fix was simple once we understood it: reroll all the nodes to get a consistent MTU configuration across the cluster.
Resolution
The Sunday call stretched past three hours. We shared screens, walked through stack traces and packet captures, validated theories. There was good collaboration with Google's team. They recognized the anetd bug immediately once we showed them the evidence. Not many customers create and delete pods at our volume, so we'd surfaced something they hadn't caught yet.
Distributed systems rarely fail in just one layer. The Wireguard crashes were the first layer. The MTU mismatch was hidden underneath, only becoming visible once we fixed the initial problem.
We watched our error dashboards until the Valkey connection failures disappeared. By the time the last errors cleared, we all felt accomplished. It was late Sunday, and we decided to monitor through Monday before declaring full victory, but the immediate crisis was over.
What We Learned
The real lesson here was about layered failures. When you fix one thing in a distributed system, you need to watch carefully for what emerges next. We're more methodical now about validation after infrastructure changes.
For Sascha, this incident changed how he approaches debugging entirely. It was the first time he leaned heavily on AI agents for investigation, and the ability to query logs at scale and surface patterns without manual parsing was a game-changer. "I haven't gone back," he said afterward.
The team also learned to trust our instincts when pushing back on vendors. Erik was right about the MTU issue even when Google's initial assessment disagreed. That kind of technical conviction matters when it comes to problems like this.
Google, for its part, has since patched the WireGuard concurrency bug. We're not the only ones who benefit from that fix.
Work on Problems Like This
If debugging complex cloud infrastructure sounds interesting to you, we're hiring at Lovable. We work on challenging technical problems every day, and we'd love to have you on the team.